[Algorithm] 해시(hash), 자바로 해시테이블 구현하기
Hash (해시)
- hashing 은 데이터를 저장할 index를 간단한 연산으로 구현하는 것
- hash function을 통해 얻어지는 값이 hash value, hash code, hash라고 함
hash table
- 데이터의 해시 값을 테이블내의 주소로 이용하는 탐색 알고리즘
- 데이터를 담을 테이블을 미리 크게 확보해 놓은 후 입력받은 데이터를 해시하여 테이블내의 주소를 계산하고 이 주소에 데이터를 담는 것
- 데이터가 입력되지 않은 여유공간이 많아야 제 성능을 유지 가능
- 해시 테이블의 각 요소를 버킷(bucket)이라고 함
hash function
- hash = (key value % hash table size )
collesion (충돌)
- hash value 가 같은 경우 충돌
- 충돌이 발생했을 때 rehashing 을 수행하여 비어있는 버킷을 찾아내는 방법
collesion 해결 법 1 - channing
- 같은 해쉬값을 갖는 데이터를 linked list에 사슬 모양으로 연결
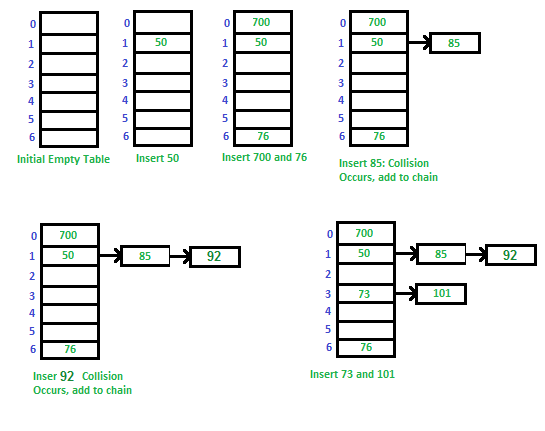
장점
- 해시 테이블이 채워지지 않으므로 언제든지 체인에 더 많은 요소 추가 가능
- 키의 삽입 또는 삭제 횟수와 빈도를 알 수 없을 때 주로 사용
단점
- 연결은 간단하지만 테이블 외부에 추가 메모리가 필요
- linked list의 단점을 가지게 됨
- 검색 시간이 O (n)이 될 수 있음
collesion 해결 법 2 - open addressing(=closed addressing)
- 모든 요소가 해시 테이블 자체에 저장
- Linear Probing , Quadratic Probing로 해시테이블내 주소를 탐색
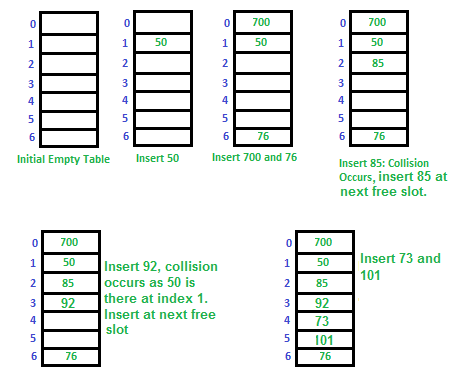
Linear Probing 선형 탐사
- 해시 함수로부터 얻어낸 주소에서 고정 폭으로 다음 주소로 이동
- 그 주소에도 다른 데이터가 있어 충돌이 발생하면 또 그 다음주소로 이동
- 해시테이블에 삽입된 데이터들은 서로 모여있는 cluster 현상이 매우 잘 발생하여, 새로운 주소를 찾는데 시간이 오래 걸릴 수 있음
Quadratic Probing 제곱 탐사
- 선형 탐사 보완법, 이동폭이 제곱수로 늘어 남
- 2차 cluster를 유도 하는 문제를 가짐
Double Hashing 이중해싱
- Open Addressed Hash 테이블의 충돌 해결 기술
- 충돌이 일어날 경우 제2의 해시함수로 계산하는 방법
- hash1 (key) = key % TABLE_SIZE
- hash2 (key) = PRIME – (key % PRIME) (PRIME : TABLE_SIZE보다 작은 소수)
rehashing
- 기본적으로 부하율이 미리 정의 된 값 (부하율의 기본값은 0.75) 이상으로 증가하면 복잡성이 증가하여 이를 극복하기 위한 방법
- 해시테이블의 크기를 늘리고, 늘어난 해시테이블의 크기에 맞추어 테이블 내의 모든 데이터를 다시 해싱
- 낮은 부하 계수와 낮은 복잡성을 유지하게 됨
java로 hash 구현
references
https://www.geeksforgeeks.org/hashing-data-structure/
https://www.geeksforgeeks.org/implementing-our-own-hash-table-with-separate-chaining-in-java/
https://www.tutorialspoint.com/data_structures_algorithms/hash_data_structure.htm