[HIVE] Hadoop과 Hadoop ecosystem(HDFS, MapReduce, HIVE)
하둡을 쓰는 환경에 있지만 SQL과 비슷한 hive를 사용하고, 내 담당 업무에서 hive를 다루는 수준은 크게 어려움이(?) 없어서 공부를 하지 않았다.
그러다가, 문득 업무 세계관(?)을 넓히기 위해 프로그램들을 살펴보다 알면 좋겠다고 느꼈다.
내 영역의 나의 업무 파트가 아닌, 앞단 프로그램인 즉, 하둡으로 구성된 데이터를 처리하는 프로그램 대해서 이해도를 높히려고 한 것이다.
근데 또 하다보니, 새로운 것들에 대한 습득에 재미를 오랜만에 느껴본다.
그렇다고 해서 아주 깊은 수준의 하둡까지 논하다긴 보다는 하둡의 기초, 하이브의 기초까지만 정리해보겠다.
아파치 하둡 (Apache Hadoop : High-Availability Distributed Object-Oriented Platform)
대용량 데이터를 분산처리할 수 있는 자바기반의 오픈소스 framework
- 원래 너치의 분산 처리를 지원하기 위해 개발된 것으로, 아파치 루씬의 하부 프로젝트
- 분산처리 시스템인 구글 파일 시스템을 대체할 수 있는 하둡 분산 파일 시스템과 맵리듀스를 구현한 것
- 데이터는 HDFS 분산파일시스템에 저장
- MapReduce 패러다임을 사용
- DATA Warehouse Application에 적합 (D/W 정적데이터분석, 빠른 응답시간 필요없음, 데이터가 자주 안 바뀜)
- 배치처리에서 유명한 오픈소스
- Hadoop은 NOSQL, RDBMS이 아니지만 상호보완.
- Hadoop이 RDBMS 대체가능? No!
- ETL1에 도움을 줌
장점
- 라이센스비용 부담이 없음
- 저렴한 구축비용 (x86CPU, 리눅스서버로 구축 가능) c.f) RDBMS은 고가의 장비. 특히 유닉스 서버는 비쌈
- 빅데이터2를 적은 비용처리하며, 비용대비 빠른 데이터처리 가능
단점
- 고가용성
- 네임스페이스 제한
- 데이터 수정불가
- POSIX 병렬처리
Hadoop ecosystem
- HDFS (Hadoop Distributed File System) : 분산시스템에 데이터 저장. 저장소 플랫폼 웹서버급 서버를 묶어서 하나의 스토리지 처럼 사용 가능. 저사양 서버를 이용해 스토리지 구성 가능 c.f) 고성능 서버는 비쌈.
- MapReduce : Data processing using programming. 로직, 알고리즘 이용해서 데이터 처리 대용량 데이터처리를 위한 분산 프로그래밍 모델
- YARN (Yet Another Resource Negotiator.) : 하둡 맵리듀스 핵심 엔진 , 병렬처리를 위한 클러스터 자원관리 및 스케쥴링 담당
- Spark : In-memory Data Processing
- PIG, HIVE : Data Processing Services using Query (SQL-like)
- HBase : NoSQL Database
- Mahout, Spark MLlib “ Machine Learning
- Apache Drill : SQL on Hadoop
- Zookeeper : Managing Cluster
- Oozie : Job Scheduling
- Flume, Sqoop : Data Ingesting Services
- Solr and Lucene : Searching & Indexing
- Ambari : Provision, Monitor and Maintain cluster
- HIVE : 하둡기반의 d/w 하우징용 솔루션
HDFS(Hadoop Distributed File System)
하둡 프레임워크를 위해 자바 언어로 작성된 분산 확장 파일 시스템
여러 기계에 대용량 파일들을 나눠서 저장
데이터들을 여러 서버에 중복해서 저장을 함으로써 데이터 안정성을 얻음
호스트에 RAID 저장장치를 사용하지 않아도 됨
- 하드웨어 오동작
- 하드웨어 수가 많아지면 그중에 일부 하드웨어가 오동작하는 것은 예외 상황이 아니라 항상 발생하는 일이라,
- 이런 상황에서 빨리 자동으로 복구하는 것은 HDFS의 중요한 목표.
- 스트리밍 자료 접근
- 범용 파일 시스템과 달리 반응 속도보다는 시간당 처리량에 최적화 되어 있음
- 큰 자료 집합
- 한 파일이 기가바이트나 테라바이트 정도의 크기를 갖는 것을 목적으로 설계되어 있음
- 자료 대역폭 총량이 높고, 하나의 클러스터에 수 백개의 노드를 둘 수 있음
- 하나의 인스턴스에서 수천만여 파일 지원
- 간단한 결합 모델
- 한번 쓰고 여러번 읽는 모델에 적합한 구조
- 파일이 한번 작성되고 닫히면 바뀔 필요가 없는 경우를 위한 것으로, 처리량을 극대화할 수 있음
- 자료를 옮기는 것보다 계산 작업을 옮기는 것이 비용이 적게 듦
- 자료를 많이 옮기면 대역폭이 많이 들기 때문에 네트워크 혼잡으로 인하여 전체 처리량이 감소 함
- 가까운 곳에 있는 자료를 처리하게 계산 작업을 옮기면 전체적인 처리량이 더 높아 짐.
- 다른 종류의 하드웨어와 소프트웨어 플랫폼과의 호환성
- 서로 다른 하드웨어와 소프트웨어 플랫폼들을 묶어 놓아도 잘 동작
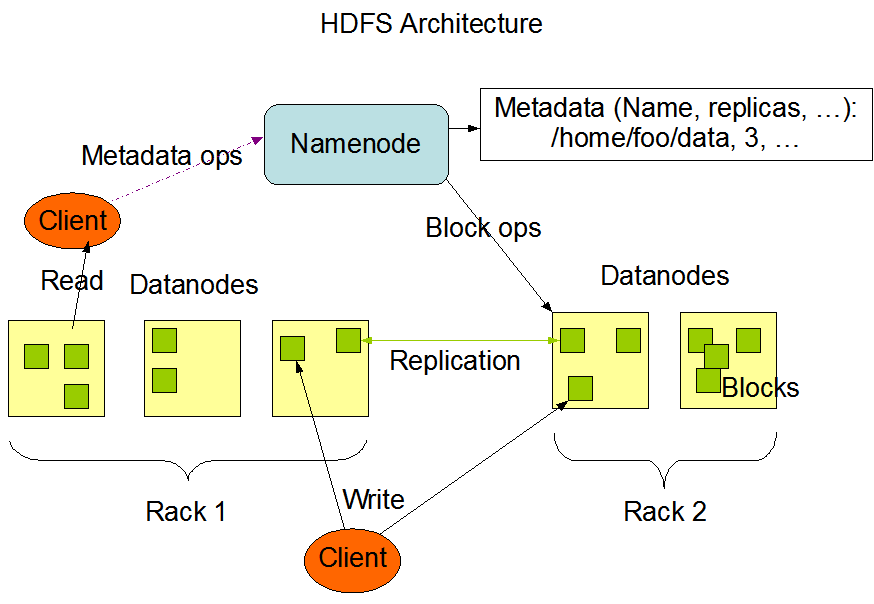
- 네임노드와 데이터노드 (마스터/슬레이브(master/slave) 구조)
- 네임노드 (master)
- HDFS 클러스터는 하나의 네임노드, 즉, 파일 시스템을 관리하고 클라이언트의 접근을 통제하는 마스터 서버로 구성되어 있음
- 네임스페이스를 공개하여서 유저 데이터가 파일에 저장되는 것을 허락
- 파일과 디렉터리의 읽기(open), 닫기(close), 이름 바꾸기(rename) 등, 파일시스템의 네임스페이스의 여러 기능을 수행
- 데이터 노드와 블록들의 맵핑을 결정
- 데이터 노드 (slave)
- 클러스터의 각 노드에는 데이터노드가 하나씩 존재하고, 이 데이터 노드는 실행될 때마다 노드에 추가되는 스토리지를 관리
- 내부적으로 하나의 파일은 하나 이상의 블록으로 나뉘어 있고, 이 블록들은 데이터노드들에 저장되어 있음
- 파일시스템의 클라이언트가 요구하는 읽기(read), 쓰기(write) 기능들을 담당
- 데이터 노드는 네임노드에서의 생성, 삭제, 복제 등과 같은 기능도 수행
- 네임노드와 데이터노드는 GNU/Linux OS를 기반으로 하는 상용머신에서 실행하기 위해 디자인된 소프트웨어의 일부
- HDFS는 자바 언어를 사용하므로 자바가 동작하는 어떠한 컴퓨터에서나 네임노드나 데이터노드 소프트웨어를 실행 가능
- 네임노드 (master)
MapReduce
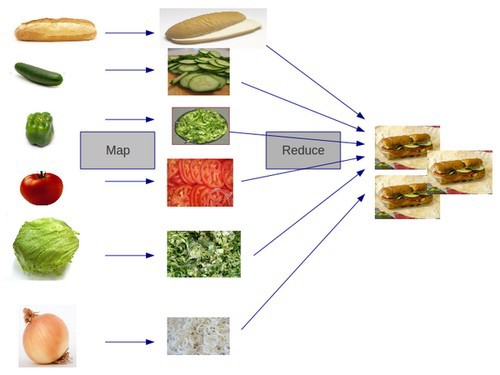
클러스트를 고르게 나누어 처리하는 프로그래밍 모델
- Map
- 맵리듀스 처리를 위해 논리적인 데이터 조각인 split으로 나누어서
- map task는 스플릿을 읽고 키/값으로 이루어지 모든 값을 map function에 넘겨 중간 파일에 결과를 저장
- Reduce
- Reducer는 중간 파일을 읽고 reduce function에 전달
- reduce task는 결과를 최종 결과 파일에 저장
- 장점
- 분산프로그램을 쉽게
- 선형의 시간으로 속도 빠름
- 수평 확장성
- 결함 허용
- 비용 효율성
- 단점
- 재귀적이나 반복적인 실행을 할 수없음
- 맵이 준비해야하는 요소들이 필요(리듀스 작업 전)하기 때문에 온라인 스트림 처리(연속적으로 처리하고 조치 취함)나 실시간(처리후 결과 바로 얻는 것)에서는 부적합
HIVE
- HIVE + SQL = HQL (Hive Query Language) : 관계형 데이터베이스의 표준과 비슷
- 하둡의 페타바이트 데이터를 다루는 SQL 질의의 표준
- HDFS의 데이터를 SQL로 접근할수 있음
- HDFS 위에서 테이블과 같은 구조로 제공
- table, partition, bucket 세개의 데이터 구조 지원
- primitive types : TIMESTAMP, STRING, FLOAT, BOOLEAN, DECIMAL, DOUBLE, INT, SMALLINT, BIGINT
-
complex types : UNION, STRUCT, MAP, ARRAY
- 장점
- 맵리듀스보다 간단, 코딩이 적은 질의 모델제공
- HQL은 SQL과 비슷
- 쉽게 분석할 수 있는 많은 함수 제공
- 빠름
- 여러 프레임워크에서 동작
- 애드혹 질의 가능
- 사용자정의 I/O 포맷 지원
- 확장과 확대 가능
- 고도화된 JDBC, ODBC 드라이버를 사용하여 데이터 얻을 수 있음
- 메타데이터 관리,인증,질의 최적화에 대해 정의된 아키텍처를 소유
- 단점
- record 단위의 삭제 안 됨(0.14.0 버전부터 가능)
- 트랜잭션 제공하지 않음 (0.13.0 버전부터 가능)
References
https://dzone.com/articles/hadoop-ecosystem-hadoop-tools-for-crunching-big-da
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
https://ko.wikipedia.org/wiki/%EC%95%84%ED%8C%8C%EC%B9%98_%ED%95%98%EB%91%A1
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
https://www.geeksforgeeks.org/hadoop-ecosystem/
도서: 하이브핵심정리 (에이콘 출판/다융 두 지음)