[HIVE] HIVE Partition, Bucket, View, Index
HIVE 쿼리 성능을 최적화 시키는 방법으로 , 파티션, 버켓, 뷰, 인덱스 가 있으며 partition, view, index 는 SQL과 유사한 부분이 많아 추측 가능(?)하지만, bucket은 생소한 부분이 있다.
파티션 Partition
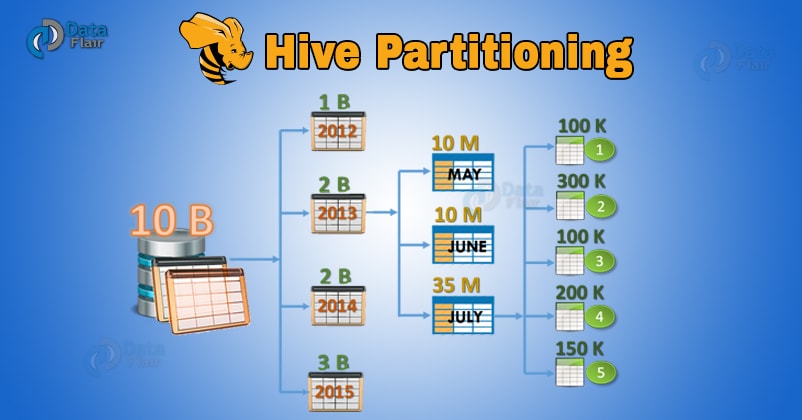
- 하이브는 데이터가 많은 테이블의 쿼리를 할때, 특히 맵리듀스 작업을 하게되면서 비효율적이게 되어 이를 파티션으로 해결 하고자 함
- HDFS 테이블 디렉토리의 하위 디렉토리에 데이터를 저장
- 너무 많은 작은 양의 파티션을 생성하게 될 경우, 많은 디렉토리를 생성하게 되어 query시 많은 디렉토리를 탐색해야 될 수 있는 점 유의
--파티션 생성
CREATE TABLE table_tab1 (id INT, name STRING, dept STRING, yoj INT)
PARTITIONED BY (year STRING);
--생성된 파티션 확인
SHOW PARTITIONS table_tab1;
--데이터를 파티션으로 적재
LOAD DATA LOCAL INPATH tab1’/clientdata/2009/file2’OVERWRITE INTO TABLE studentTab PARTITION (year='2009');
LOAD DATA LOCAL INPATH tab1’/clientdata/2010/file3’OVERWRITE INTO TABLE studentTab PARTITION (year='2010');
정적 파티셔닝 Static Partitioning
- insert문에 고정값을 전달
- 테이블의 큰 파일을 로드할 때 적절
- 파티션 변경 가능
INSERT INTO TABLE table_name(yyyymmdd='20200524') SELECT name FROM temp;
동적 파티셔닝 Dynamic Partitioning
- insert문에 조회하는 컬럼을 전달
- 파티셔닝 되지않은 테이블을 로드하는 것
- 정적 파티션보다 시간이 오래 걸림
- 대용량 데이터가 저장되어 있는 경우 적합
- 컬럼정보이용하여 동적으로 파티션이 생성 되어 쿼리를 이용하는 시점에서 알수 있음
- 파티션 변경 할 수 없음
INSERT INTO TABLE table_name(yyyymmdd) SELECT name FROM temp;
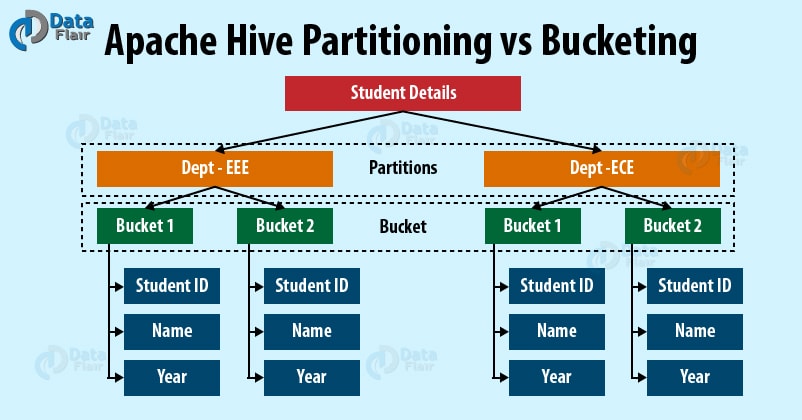
버켓 Bucket
- HDFS에서 분리된 파일로 데이터를 저장
- 특정 컬럼(ID)을 버킷컬럼 으로 사용 -> 해당 컬럼의 값은 사용자 정의 숫자로 컬럼에 해쉬처리 ->동일한 ID를 가진 레코드는 항상동일한 버킷에 저장
- 버킷의 갯수는 2의 N제곱개로 추천. 블록크기가 256MB이면 각버킷에 512MB 데이터 계획 할수 있음.
- 샘플링, map-side joins 작업시 보다 효율적
--버킷 생성
CREATE TABLE table_name
PARTITIONED BY (partition1 data_type, partition2 data_type,….)
CLUSTERED BY (column_name1, column_name2, …)
SORTED BY (column_name [ASC|DESC], …)]
INTO num_buckets BUCKETS;
뷰 VIEW
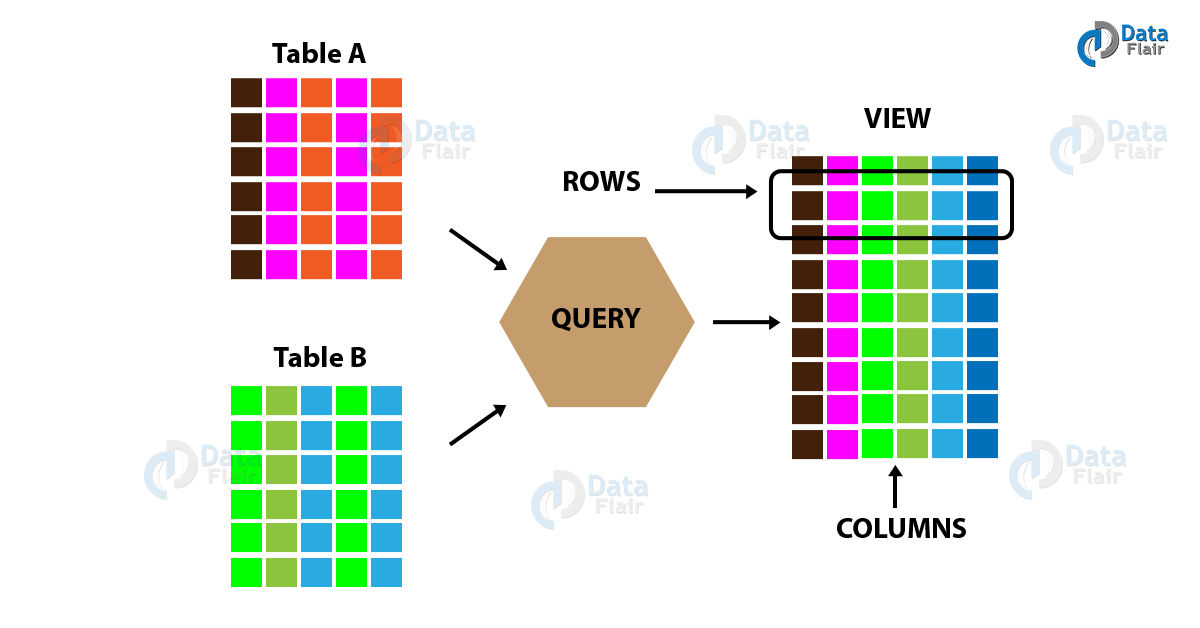
- SQL의 뷰와 유사함 (virtual tables)
- 뷰는 조인, 서브쿼리, 데이터 필터, 데이터 평탄화 같은 복잡성을 숨겨서 쿼리를 간단하게 만드는데 사용되는 논리적인 데이터 구조
- 하이브 뷰는 데이터를 저장하거나 실체화된 데이터가 없어서 뷰가 생성되자마자 뷰의 스키마가 고정이 됨 -> 기본테이블 스키마 변경시 뷰 스키마에 반영 안됨
- DML 사용 가능
--뷰 생성
CREATE VIEW [IF NOT EXISTS] view_name [(column_name [COMMENT column_comment], …) ]
[COMMENT table_comment]
AS SELECT …
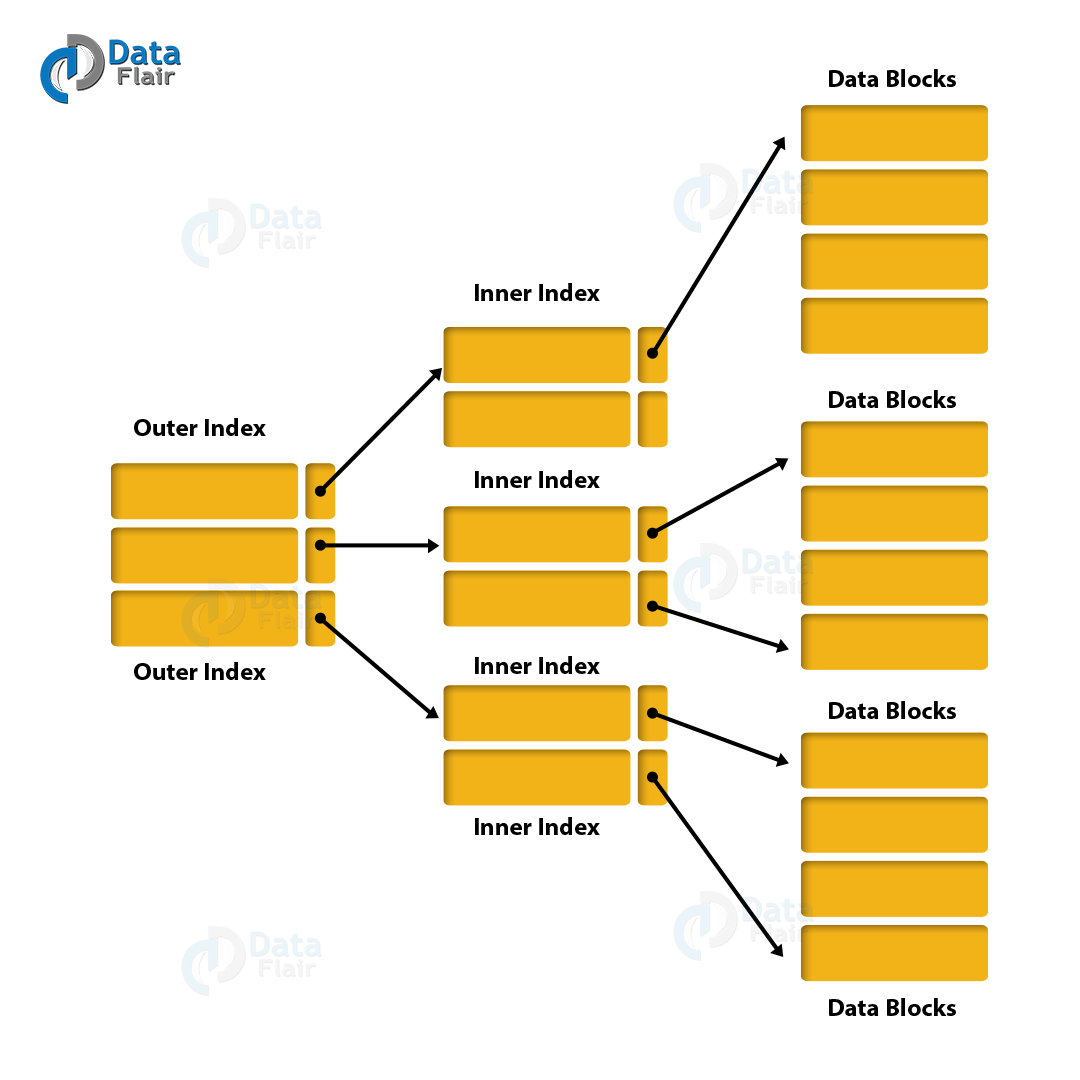
인덱스 INDEX
- 테이블의 특정 열에 포인터를 만든다는 것
- 사용자가 직접 정의해야하며, 테이블 따로 관리됨
- 데이터 크기에 따라 파티션을 지원
--인덱스 생성
Create INDEX < INDEX_NAME> ON TABLE < TABLE_NAME(column names)>
References
https://data-flair.training/blogs/apache-hive-partitions/
https://data-flair.training/blogs/hive-view-hive-index/
https://beyondcorner.com/learn-apache-hive/hive-view-and-index/
https://wikidocs.net/23557