[HIVE] HIVE SELECT Order/Sort/Distribute/Cluster By(정렬), Group By(집계)
SELECT
SELECT Syntax
- SELECT * 는 맵리듀스 작업 실행하지 않고 모든 테이블/파일 스캔하기 때문에 SELECT
문보다 빠름 - WHERE절 에서 컬럼앞에 앨리언스 사용해야 하며, 사용하지 않을 경우 에러 남
error : 'Correlation expression cannot contain unqualified column references' - 서브쿼리는 WHERE 절의 오른쪽 부분에 위치
- 중첩서브쿼리를 사용 할 수 없음
- IN, NOT IN 문은 하나의 컬럼만 지원
WITH CommonTableExpression (, CommonTableExpression)*]
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT [offset,] rows]
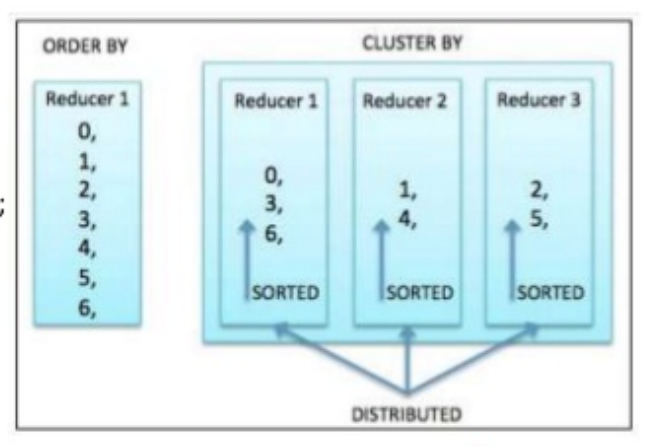
정렬 (ordering, sorting)
ORDER BY
- SQL의 ORDER BY 와 비슷
- 기본은 오름차순 (ASC)
- 리듀서가 생성한 결과에서 정렬된 순서유지
- LIMIT을 함께 사용할 것을 추천
-- LIMIT은 조회되는 로우 갯수 제한하며, RDMBS에서 ROWNUM와 유사
SELECT * FROM customers ORDER BY create_date LIMIT 5
SORT BY
- 리듀서로 보내기 전 정렬하기 때문에 하나의 리듀서에서만 정렬 보장
- 리듀서를 1개만 사용한다면 ORDER BY와 결과가 동일
SET mapred.reduce.tasks=1
DISTRIBUTE BY
- SORT BY 사용시 앞에 명세해야 함
- 매퍼 결과 DISTRIBUTE BY에 의해 컬럼 값이 일치하는 로우는 동일한 리듀서로 파티션 되어 짐
- 매퍼에서 어느 리듀서로 결정할지 여부의 관점에서 볼때, SQL의 GROUP BY와 비슷
SELECT col1, col2 FROM t1 DISTRIBUTE BY col1 SORT BY col1 ASC, col2 DESC
CLUSTER BY
- 동일한 그룹의 칼럼에 대해 DISTRIBUTE BY, SORT BY명령을 수행
- 내부적으로 각 리듀서에서 정렬됨
- ASC/DESC 지원안함
집계 (aggregation)
GROUP BY / GROUPING SET
- 여러 GROUP BY의 결과 집합에 UNION 을 연결하는 결과가 GROUPING SET
/* 아래 두개의 쿼리가 동일한 결과가 나옴*/
--GROUPING SET
SELECT a, b, SUM(c) FROM tab1 GROUP BY a, b GROUPING SETS ( (a,b) )
--GROUP BY
SELECT a, b, SUM(c) FROM tab1 GROUP BY a, b
/* 아래 두개의 쿼리가 동일한 결과가 나옴*/
--GROUPING SET
SELECT a, b, SUM( c ) FROM tab1 GROUP BY a, b GROUPING SETS ( (a,b), a)
--GROUP BY
SELECT a, b, SUM( c ) FROM tab1 GROUP BY a, b
UNION
SELECT a, null, SUM( c ) FROM tab1 GROUP BY a
CUBE
- CUBE문은 특정 그룹핑한 칼럼을 받고 모두 가능한 조합에 대한 집계 생성
- n개의 칼럼을 지정하면, 2의n제곱 개를 조합한 집계 리턴 (2의3제곱=8개)
/* 아래 두개의 쿼리가 동일한 결과가 나옴*/
GROUP BY a, b, c WITH CUBE
GROUP BY a, b, c GROUPING SETS ( (a, b, c), (a, b), (b, c), (a, c), (a), (b), (c), ( ))
ROLLUP
- n개의 컬럼을 지정하면, n+1레벌의 집계 생성
/* 아래 두개의 쿼리가 동일한 결과가 나옴*/
GROUP BY a, b, c WITH ROLLUP
GROUP BY a, b, c GROUPING SETS ( (a, b, c), (a, b), (a), ( ))
References
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Select
https://www.guru99.com/hive-queries-implementation.html#2
https://www.slideshare.net/WillDu1/ten-tools-for-ten-big-data-areas-04apache-hive
도서: 하이브핵심정리 (에이콘 출판/다융 두 지음)